
| UP PREV NEXT |
gate count 1628 number of cells 541 number of library cells 188 number of used cells 55 max fanin 17 max input capacitance 214 max internal fanout 34 critical path 0fF 2103 critical path 6fF 2493 |
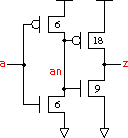
In this experiment a set of non-inverting buffers is added to the library. These are the drive strengths x05,x1,x2,x3,x4, x6,x8,x12, plus a special buffer, the bf1v4x1 which uses a first inverter with minimum transistor sizes and input capacitance.
| bf1v0x1 schematic | bf1v4x1 schematic |
| |
|
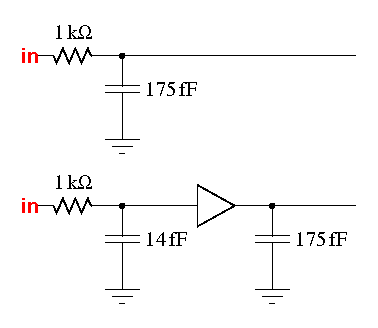 There are two principal ways in which the buffers can
improve the critical path.
There are two principal ways in which the buffers can
improve the critical path.
CONSTANT cin_a : NATURAL := 17; CONSTANT rdown_a_z : NATURAL := 290; CONSTANT rup_a_z : NATURAL := 370; CONSTANT tpll_a_z : NATURAL := 89; CONSTANT tphh_a_z : NATURAL := 73; |
- the unbuffered input delay is 1 × 214 = 214ps
- the buffered input delay is 1 × 17 = 17ps
- the buffer rise delay is 73 + 0.37 × 214 = 152ps
- the buffer fall delay is 89 + 0.29 × 214 = 151ps
- the average buffer delay is 152ps
So the average total buffered input delay is 17 + 151 = 168ps, which is less than 214ps without the buffer.
LOON has five optimisation levels, from 0-4. At levels 0 and 1, decoupling buffers are never inserted. At levels 2-4, decoupling buffers will be inserted if LOON calculates that they improve the critical path speed. The problem is that optimisation level 4 is the one which most favours speed over area, but there is no user control over whether decoupling buffers are inserted or not. In a synthesis flow which successively optimises the netlist with LOON, one can easily find that decoupling buffers are inserted too soon into the netlist.
It is better in fact to optimise the netlist without any inserted buffers, and then see whether further optimisations with buffers give any speed improvement. The optimised netlist is the one from the previous experiment, and using LOON with buffers in the library, the critical path can be reduced by 0.2% at the cost of a 0.2% area increase and three inserted buffers.
If instead the LOON optimisation starts with a library containing buffers, the final critical path is actually slower by 0.6%, although the area is reduced by 1.8%.
| Comparison of LOON synthesis with buffers | ||
| critical path (ps) | gate count | |
| LOON synthesis with no buffers | 2497 | 1625 |
| LOON synthesis using buffers | 2512 | 1595 |
| LOON synthesis using buffers only at end | 2493 | 1628 |
The result of this is the need to supply five synthesis libraries for the Alliance synthesis flow.
alliance/vbeand for the vsclib with 0.13µm timing have the names
vsclib013_b vsclib013_nobuf vsclib013_6_nobuf vsclib013 vsclib013_6Other wireload libraries can be easily made as, inside the 6fF wireload directories there is a script which makes the library files from the 0fF wireload directory.
Buffer insertion on the inputs can be problematic with LOON and will be handled in a special way in the next experiment.
| Table of synthesis results | |||||||
| critical path (ps) | gate count | cell count | porosity | library cells | used cells | ||
| synthesis 1 | 4279 | 1561 | 923 | 43% | 9 | 8 | basic inverters, NAND & NOR gates |
| synthesis 2 | 4236 | 1472 | 792 | 45% | 15 | 12 | AND & OR gates |
| synthesis 3 | 4157 | 1357 | 696 | 46% | 19 | 16 | AOI & OAI gates, 2/1 and 2/2 |
| synthesis 4 | 4157 | 1357 | 696 | 46% | 20 | 16 | mxi2 2-way inverting mux |
| synthesis 5 | 3983 | 1343 | 668 | 48% | 21 | 16 | cgi2 carry generator inverting |
| synthesis 6 | 3948 | 1352 | 668 | 48% | 28 | 18 | inverters with multiple drive strengths |
| synthesis 7 | 3061 | 1433 | 666 | 51% | 70 | 27 | x2 drive strengths for all functions |
| synthesis 8 | 3056 | 1456 | 666 | 52% | 70 | 30 | BOOG with x1 drive strengths |
| synthesis 9 | 2960 | 1476 | 666 | 53% | 70 | 32 | BOOG with x05 drive strengths |
| synthesis 10 | 2963 | 1480 | 666 | 53% | 76 | 34 | nd2a and nr2a cells |
| synthesis 11 | 2963 | 1480 | 666 | 53% | 79 | 34 | nd2ab type of 2-OR |
| CyHP library | 3778 | 1539 | 832 | 46% | 18 | 17 | Minimum size library |
| synthesis 12 | 2908 | 1362 | 553 | 54% | 91 | 38 | AND/OR into XOR/XNOR |
| synthesis 13 | 2893 | 1378 | 551 | 55% | 103 | 39 | aoi211, aoi31, oai211 & oai31 |
| synthesis 14 | 2931 | 1400 | 562 | 55% | 104 | 38 | 3-XOR gate, 1/2 stage delays |
| synthesis 15 | 2886 | 1390 | 536 | 56% | 109 | 40 | 3-XOR/XNOR gates as 2×2-I/P gates |
| synthesis 16 | 2665 | 1514 | 538 | 60% | 136 | 46 | x3 drive strength cells |
| synthesis 17 | 2567 | 1571 | 540 | 61% | 155 | 49 | x4 drive strength cells |
| synthesis 18 | 2523 | 1611 | 540 | 62% | 167 | 49 | x6 drive strength cells |
| synthesis 19 | 2497 | 1625 | 538 | 62% | 179 | 54 | x8 drive strength cells |
| synthesis 20 | 2493 | 1628 | 541 | 62% | 188 | 55 | buffers to decouple non-critical paths |
| UP PREV NEXT |